





《张江科技评论》
开博时间:2019-06-06 14:03:00《张江科技评论》是由上海科学技术出版社与上海市张江高科技园区管理委员联合创办的一本科技评论类杂志。该刊报道评价国内外创新性科学技术的发展趋势及其商业价值,介绍上海在建设全球领先科创中心进程中的制度成果、技术成果、创业成果,推动产学研密切协作,促进科技成果转化,服务经济转型发展。




当心理学遇上大数据
2021-10-20 13:55:00当心理学遇上大数据,究竟能擦出怎样的火花?通过分析用户生态化的行为数据开展无侵扰的心理学研究,其结果更具有可推广性。

心理学作为一门研究心理现象及其规律的科学,具有悠久的历史。19世纪中叶以前,心理学研究以思辨式为主,很难称之为科学。德国心理学家威廉?冯特于1879年在德国莱比锡大学创建了世界上第一个专门的心理学实验室,把实验法引进心理学,科学心理学由此诞生。
目前,科学心理学的研究建立在客观数据的基础之上。然而,由于条件所限,长期以来心理学研究的样本规模都十分有限,一般多采用抽样的方式,再把局部样本的研究结果推广到总体上,这就使研究结论的有效性不可避免地受到样本代表性的影响。此外,传统方法大多依赖于用户自陈,数据收集过程也比较缓慢。
大数据理论与技术的出现,特别是移动互联网的普及,极大地拓展了数据采集的广度和深度,使研究人员有可能针对极大规模用户开展研究,进行全时全程的跟踪记录,并实现数据颗粒度的灵活变化,从而使心理学研究的数据基础更全面、坚实。利用大数据信息采集与处理技术,可以实现对个体和群体外部表现数据的实时采集,弥补传统研究方法时效性不足的缺点。
基于此,研究人员利用网络大数据开展多个层面的研究,利用机器学习模型根据用户网络行为进行心理特征的识别。利用预测模型,使研究人员通过分析用户生态化的行为数据开展心理学的相关研究成为可能,这种无侵扰的心理研究使结果更具有可推广性。
利用机器学习建立基于行为数据的人格预测模型
人格(personality)是心理科学领域中的重要研究课题,涵盖了个体稳定的行为模式与内部心理过程,能够解释存在于人与人之间的稳定的个性化差异,并且能够与个体、人际、社会等多个研究层面上的结果变量同时保持着稳定的预测关系。心理学家已经建立了许多关于人格的理论和模型,具有代表性的理论有卡特尔人格特质理论、艾森克三因素理论、塔佩斯大五人格理论和特里根七因素理论。其中,大五人格模型(Five-factor model或Big-Five)是目前使用最广泛的人格模型之一,它将人格分为5个因子:开放性(Openness)、尽责性(Conscientiousness)、外倾性(Extroversion)、宜人性(Agreeableness)和神经质(Neuroticism)。传统的人格测量方法主要是通过自陈量表的方式来进行。但是,由于自陈量表需要用户人工填写,难以实现针对大规模用户的实时测量,亟待改善。
近年来,随着社交网络和社会媒体的兴起,有研究开始尝试利用用户的网络留痕预测其人格,并已经获得了理想的预测效果。2013年,英国剑桥大学的米夏尔?科辛斯基(Michal Kosinski)、戴维?史迪威(David Stillwell)和微软研究院的托雷?格雷佩尔(Thore Graepel)利用脸书(Facebook)的“like”(类似于关注、点赞)这一属性,抽取用户行为特征矩阵,实现了对用户大五人格指标的自动识别。2015年,英国剑桥大学的吴又又和科辛斯基、史迪威发现,随着纳入特征矩阵的“like”数目的增多,对用户人格识别的准确度甚至能超过家人对他/她的了解程度。
我们利用新浪微博,通过机器学习建立了基于用户的微博行为的人格预测模型。我们引入动态行为的概念,提出两种提取动态行为的时序特征方法,从而挖掘能够预测人格的复杂行为模式。通过在线的微博用户实验,被试填写人格问卷的形式,我们获取了547个用户的人格得分,并利用微博API下载用户的在线微博数据。利用两种特征提取方法,分别提取了845和795个特征。对于第一个特征集(845个特征),在大五人格每个维度,我们分别训练了连续预测模型和分类模型,连续模型的相关性系数为0.48~0.54,分类模型的精确度(Accuracy)在84%~92%;对于第二个特征集(795个特征),训练的连续预测模型,其预测的人格数值与真实用户填写问卷获取的人格得分的相关性系数为0.5~0.63。
研究发现,利用微博行为对人格进行预测的最佳观察周期(出现最优的模型精度的时间段)一般会出现在90到120天之间。但是,对不同的人格维度,利用微博行为来预测人格存在着难度水平的差异。例如,预测用户的开放性维度相对容易(模型的预测精度随着观察周期的延长快速提高,30天后达到收敛),而预测用户的宜人性维度则相对困难(模型的预测精度随着观察周期的延长缓慢提高,并且预测精度的变化趋势不稳定)。这与既有研究的结论保持一致。
研究结果表明,利用用户的网络行为来预测用户的人格特征是可行的,这为改善人格测量方法提供了新的视角。由于研究所收集的行为均是客观的,同时模型的预测精度较高,因此基于网络行为分析的人格预测方法能够克服传统人格测量方法的不足(如数据追踪困难、资源消耗巨大、测验效率低下等),从而为人格研究提供有力的研究工具,并且为其他相关研究领域提供有益的借鉴。
由于网络数据具有时间可回溯性,我们可以利用心理计算模型获取任意时间点的用户心理特征指标,通过生态化识别(Ecolouical Recognition,ER)大大扩展了传统的心理学研究范畴,使开展跨时空的心理学研究成为可能。
心理计算模型应用于家庭暴力的跨时空研究
家庭暴力(domestic violence)广泛存在于世界各国的家庭之中,全世界大约三分之一的妇女在一生中曾经遭受亲密伴侣的身体和/或性暴力或者非伴侣的性暴力。家庭暴力不仅带来身体损害,更造成精神伤害。身体损害指家庭成员以殴打、捆绑、残害等方式,对受害者的身体健康造成的危害。比身体伤害更为普遍、更难以恢复的是对受虐者的精神伤害。其中,抑郁、自杀意念是家庭暴力受害者经常出现的两大心理症状。
在对家庭暴力的影响,尤其是对受害者心理的影响研究时,常用的研究法包括量表法、个案法或两者相结合的方式。这些测量方式存在一定的不足,使得结果代表性较差,无法进行实时检测,很难获取被试以往时刻的心理状态。因此,若想要更加简单、高效地测量个体心理特征的变化,需要寻找更为直接的测量方法。
为了研究家庭暴力对受害者抑郁程度的影响,我们对受害者初次受到家庭暴力前后抑郁程度的变化进行了分析。取受害者受到初次报告家庭暴力的时间点,将受害者与对照组在此时间点前后一个月的微博文字与行为数据代入心理计算模型,比较受害者与对照组在受到家庭暴力前后抑郁程度变化,以印证家庭暴力对于受害者抑郁的影响程度。
结果表明,家庭暴力受害者在首次经历家庭暴力之后,抑郁程度显著升高;身体暴力与精神暴力均会造成受害者短时间抑郁程度的增加;夫妻间家庭暴力受害者、受虐儿童在家庭暴力过后的一个月内,抑郁程度均显著增加;而目睹亲人家庭暴力的受害者在家庭暴力发生一个月内抑郁程度没有显著变化。
由于网络可以记录大量的用户行为数据与文本数据,我们得以追踪家庭暴力受害者首次遭遇家庭暴力之前的心理状态,并以此为基线进行家庭暴力前后的心理状态对比。利用计算模型可以跨时计算微博用户任意时刻的心理特征,并且可以快速对其在相关时间内的心理特征进行计算,快速进行追踪研究。
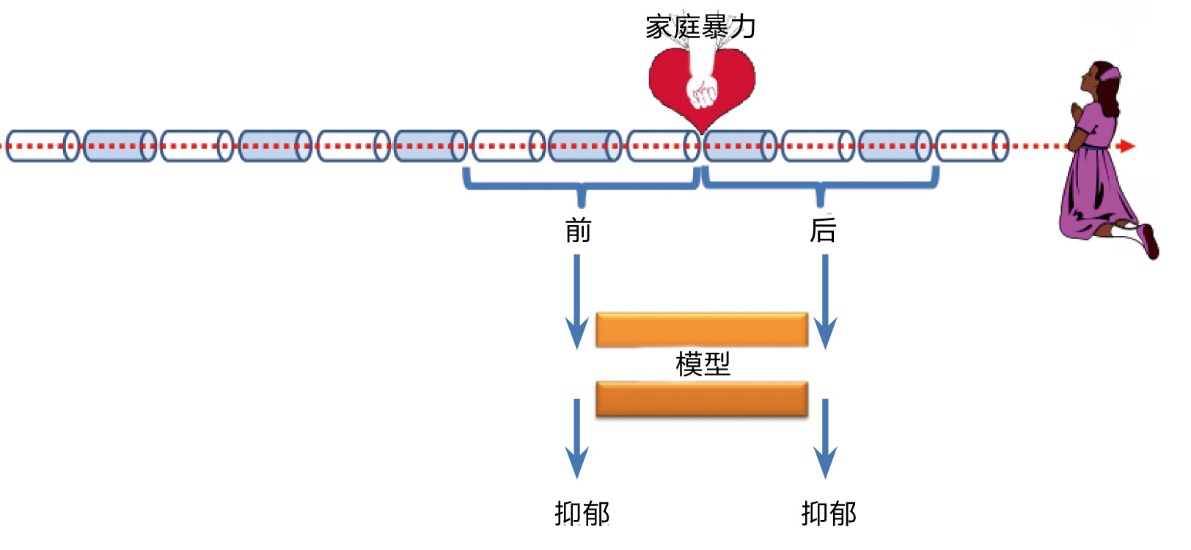
利用网络数据,根据抑郁预测模型获取家庭暴力前后的抑郁程度
心理计算模型应用的合规使用至关重要
2018年3月17日英国BBC报道,英国剑桥大学的心理学讲师亚历山大?科甘(Aleksandr Kogan)通过一款用于科研目的的Facebook的心理测试小程序收集了约27万用户数据并转手卖给了第三方,其中就包括“著名”的Cambridge Analytica公司。这家公司因为辅助特朗普赢得2016年美国大选而名声大噪。他们通过选民的Facebook数据计算出其心理特点,进而有针对性地为特朗普投放竞选广告。
人们在震惊之余,开始认真思考在以社交网络为代表的大数据时代,人工智能该如何合理应用。这些问题在学术界也已有若干讨论与共识,这次Facebook事件让我们更加关切数据使用中的伦理问题。
网络产生的海量用户行为数据,虽然是隐私泄露的重大隐患,但也是科学研究的资源宝库。合理分析利用这些数据,能够获得大量关于人类行为与心理的新知,不仅能有力地促进心理学、社会学等基础学科和人工智能技术的发展,更能为解决诸如社交问题、心理健康问题、学习效率问题、自杀问题等实际挑战带来新的曙光。社交网络行为数据由大众自发产生,也应当被用于旨在增进大众福利的探索与实践。
在Facebook事件曝光之后,不仅公众反应强烈,互联网巨头们也纷纷表态强调对用户隐私的保护,表达了“隐私是基本人权”“数据是个人资产”“保护信息安全是公司责任”等原则性观点,欧盟GDPR法令也于2018年5月25日正式生效。同时,人们也意识到数据得到合理利用而不被浪费的重要性。那么,怎样利用这些数据才是可以接受的?就操作层面而言,关键是保障用户对数据被使用的知情权与选择权。
目前,学术界经过一段时间的讨论和实践,达成了基本共识:基于网络行为心理的研究同样应当遵守人类被试研究的一般伦理原则,使用需要用户授权的数据必须征得用户的知情同意,并严格按照经由伦理委员会审核批准的程序进行,尤其不能将研究数据用于伦理委员会批准范围之外的目的(如转卖给第三方)。对那些开放的无须用户授权的网络数据,在用于科研时也应同时满足以下标准:(1)用户对数据公开是知情的;(2)数据收集后应匿名处理;(3)研究中不存在与用户的互动和沟通;(4)在公开发表物中不得出现能够识别用户个人身份的信息。
技术发展为人们的生活带来极大的便利,人工智能的发展和应用更是人类技术与产业进步的希望所在。我们不可能也不应该因噎废食,因存在个人隐私泄露的风险而废止相关网络数据的分析和利用。我们真正需要做的,是用制度和规则来规范对网络平台用户数据的使用,使之在法律和道德的框架之内有序运行,这样才能避免类似丑闻再次发生,保证网络行为数据这一由大众产生出的宝藏最终服务于增进大众的福祉、促进人类进步。
朱廷劭,中国科学院心理研究所研究员。
本文来自《张江科技评论》






